🚀 Attention Mechanism
1. Attention Mechanism Overview
import torch
import torch.nn as nn
class AttentionLayer(nn.Module):
def __init__(self, input_dim, output_dim):
super(AttentionLayer, self).__init__()
self.query = nn.Linear(input_dim, output_dim)
self.key = nn.Linear(input_dim, output_dim)
self.value = nn.Linear(input_dim, output_dim)
def forward(self, query, key, value):
scores = torch.matmul(self.query(query), self.key(key).transpose(-2, -1))
attention_weights = nn.functional.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, self.value(value))
return output
Understanding Attention Mechanism
Attention mechanisms allow models to selectively focus on certain parts of the input, which helps the model to capture important information dynamically. In a typical attention mechanism, three key components are involved:
- Query (Q): Represents the element seeking information.
- Key (K): Represents the elements from which the information is retrieved.
- Value (V): Represents the actual data or information to be retrieved.
The idea behind attention is that we compute a similarity score between the query and key and use that score to weight the corresponding value. The resulting weighted sum is the output of the attention mechanism.
Explanation of Each Component
1. Initialization (__init__ Method)
self.query = nn.Linear(input_dim, output_dim)
self.key = nn.Linear(input_dim, output_dim)
self.value = nn.Linear(input_dim, output_dim)
- Linear Layers for Query, Key, and Value: The attention mechanism requires learning projections for the input data to create the query, key, and value vectors. This is done via three separate
nn.Linearlayers, each of which maps the input data to an output space with dimensionsoutput_dim.self.query: Takes the input and transforms it into the query vector.self.key: Transforms the input into the key vector.self.value: Transforms the input into the value vector.
Each of these transformations allows the network to learn how to represent the input in a way that’s useful for computing attention.
2. Forward Pass (forward Method)
scores = torch.matmul(self.query(query), self.key(key).transpose(-2, -1))
attention_weights = nn.functional.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, self.value(value))
2.1 Query, Key, and Score Calculation
scores = torch.matmul(self.query(query), self.key(key).transpose(-2, -1))
self.query(query): Transforms thequeryinput through the query linear layer. This results in a matrix representing the “questions” that the model is asking about the input.self.key(key): Similarly, transforms thekeyinput. This represents the “possible answers” to the queries.transpose(-2, -1): Transposes the key matrix to match the dimensions required for matrix multiplication. This ensures that whenqueryandkeyare multiplied, the multiplication happens along the right dimensions.torch.matmul(self.query(query), self.key(key).transpose(-2, -1)): Performs matrix multiplication between the query and transposed key matrices to compute the attention scores. The result is a matrix of scores that indicate the alignment between each query and each key.
2.2 Attention Weights
attention_weights = nn.functional.softmax(scores, dim=-1)
- Softmax Activation: After computing the scores, we normalize them using the softmax function along the last dimension (
dim=-1). The softmax function converts the scores into probabilities, where higher values represent a stronger alignment between query and key. These probabilities are the attention weights.
2.3 Weighted Sum of Values
output = torch.matmul(attention_weights, self.value(value))
- Value Transformation:
self.value(value)transforms the input data into the value vectors, which contain the information the model will use. - Weighted Sum: The attention weights are then applied to the value vectors through matrix multiplication (
torch.matmul). This operation gives more importance to the values corresponding to high attention weights, resulting in the final output of the attention mechanism.
How the Attention Mechanism Works in This Code:
-
Learned Representations: The query, key, and value inputs are passed through learned linear transformations, which adaptively project the data into a new space.
-
Scoring: The code computes attention scores by multiplying the query and key matrices. These scores indicate how strongly the model should focus on certain parts of the input.
-
Attention Weights: The scores are passed through a softmax layer to normalize them into probabilities (attention weights).
-
Output: Finally, the attention weights are applied to the values. The values with higher attention scores have more influence on the final output. This allows the model to dynamically focus on different parts of the input during the forward pass.
2. Attention Mechanism in Machine Translation
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim, embed_dim, hidden_dim, num_layers):
super(Encoder, self).__init__()
self.embed = nn.Embedding(input_dim, embed_dim)
self.rnn = nn.LSTM(embed_dim, hidden_dim, num_layers)
def forward(self, input_seq):
embedded = self.embed(input_seq)
outputs, (hidden, cell) = self.rnn(embedded)
return outputs, hidden, cell
class Decoder(nn.Module):
def __init__(self, output_dim, embed_dim, hidden_dim, num_layers, attention):
super(Decoder, self).__init__()
self.embed = nn.Embedding(output_dim, embed_dim)
self.rnn = nn.LSTMCell(embed_dim + hidden_dim, hidden_dim)
self.attention = attention
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, input, hidden, cell, encoder_outputs):
embedded = self.embed(input)
attended = self.attention(hidden, encoder_outputs)
rnn_input = torch.cat([embedded, attended], dim=2)
hidden, cell = self.rnn(rnn_input, (hidden, cell))
output = self.out(hidden)
return output, hidden, cell
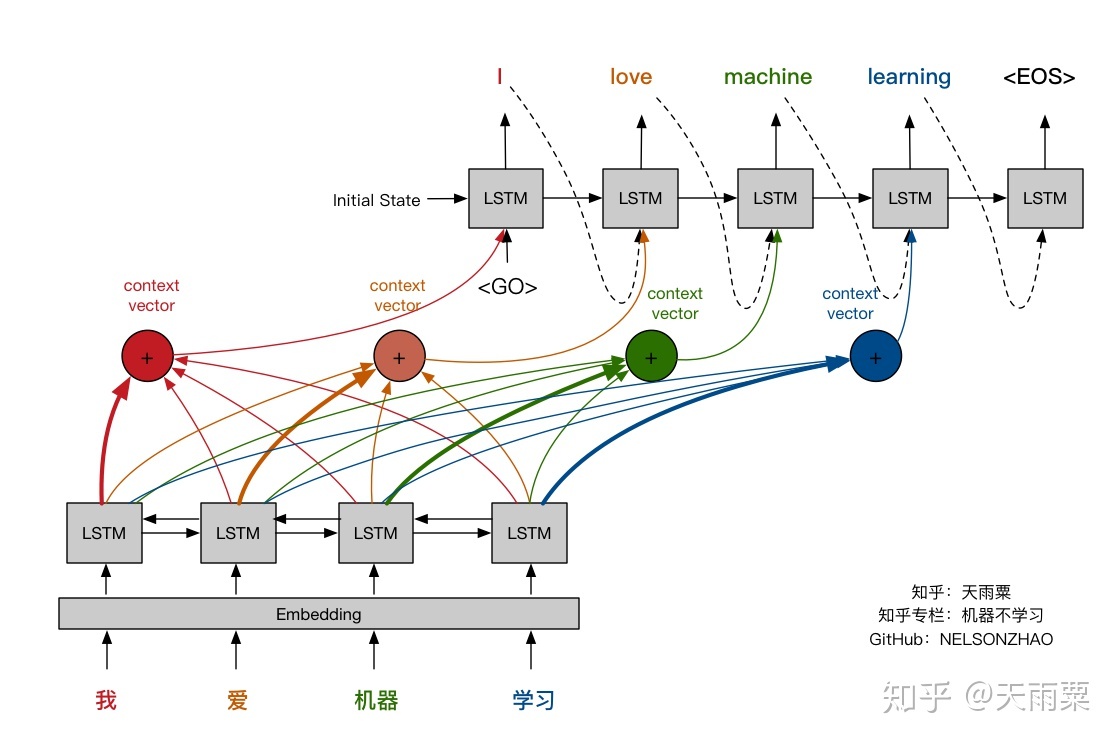
This code implements a sequence-to-sequence (Seq2Seq) model using an Encoder-Decoder architecture with attention. This architecture is commonly used in tasks like machine translation, text generation, and other sequence-based learning tasks. The model is composed of two main parts:
- Encoder: Encodes the input sequence into a set of hidden states.
- Decoder: Decodes the hidden states from the encoder to generate an output sequence. In this case, the decoder is augmented with an attention mechanism that allows it to focus on different parts of the encoded sequence.
Let’s break down the code from first principles.
Encoder
class Encoder(nn.Module):
def __init__(self, input_dim, embed_dim, hidden_dim, num_layers):
super(Encoder, self).__init__()
self.embed = nn.Embedding(input_dim, embed_dim)
self.rnn = nn.LSTM(embed_dim, hidden_dim, num_layers)
def forward(self, input_seq):
embedded = self.embed(input_seq)
outputs, (hidden, cell) = self.rnn(embedded)
return outputs, hidden, cell
Encoder Components:
- Embedding Layer (
self.embed):- Converts the input sequence of token indices into dense vectors of size
embed_dim. This embedding layer maps discrete tokens (like words or characters) into continuous-valued vectors that capture semantic meaning. - Example: In a machine translation task, each word in a sentence is transformed into a learned vector.
- Converts the input sequence of token indices into dense vectors of size
- LSTM (
self.rnn):- The
nn.LSTMlayer is used to process the embedded input sequence. LSTM (Long Short-Term Memory) is a type of recurrent neural network (RNN) that is able to capture long-term dependencies in the input sequence by using gates to control the flow of information. - Input to LSTM: The embedded input sequence (of size
embed_dim) is fed into the LSTM. - Output of LSTM: The LSTM produces two outputs:
outputs: The hidden states for all time steps.(hidden, cell): The final hidden state and cell state, which represent a summary of the sequence.
- The
Encoder Forward Pass:
def forward(self, input_seq):
embedded = self.embed(input_seq)
outputs, (hidden, cell) = self.rnn(embedded)
return outputs, hidden, cell
- Input Sequence (
input_seq): This is the sequence of token indices representing the input (e.g., a sentence in a source language). - Embedding (
self.embed(input_seq)): Each token in the input sequence is mapped to its corresponding embedding vector. - LSTM Processing (
self.rnn(embedded)): The embedded sequence is passed through the LSTM. The outputoutputscontains the hidden states for each token in the sequence, andhiddenandcellare the final hidden and cell states of the LSTM.
The encoder returns:
outputs: Hidden states of the entire input sequence.hidden,cell: Final hidden and cell states, which summarize the input sequence and are passed to the decoder.
Decoder with Attention
class Decoder(nn.Module):
def __init__(self, output_dim, embed_dim, hidden_dim, num_layers, attention):
super(Decoder, self).__init__()
self.embed = nn.Embedding(output_dim, embed_dim)
self.rnn = nn.LSTMCell(embed_dim + hidden_dim, hidden_dim)
self.attention = attention
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, input, hidden, cell, encoder_outputs):
embedded = self.embed(input)
attended = self.attention(hidden, encoder_outputs)
rnn_input = torch.cat([embedded, attended], dim=2)
hidden, cell = self.rnn(rnn_input, (hidden, cell))
output = self.out(hidden)
return output, hidden, cell
Decoder Components:
- Embedding Layer (
self.embed):- Like the encoder, the decoder has an embedding layer that maps token indices from the target sequence (output sequence) to dense vectors of size
embed_dim.
- Like the encoder, the decoder has an embedding layer that maps token indices from the target sequence (output sequence) to dense vectors of size
- Attention Mechanism (
self.attention):- The attention mechanism allows the decoder to focus on different parts of the input sequence (encoded by the encoder) at each step of decoding.
- Attention works by computing a weighted sum of the encoder’s hidden states based on how relevant each hidden state is to the current decoder hidden state.
- This means that instead of using just the final hidden state from the encoder, the decoder can selectively “attend” to different parts of the input sequence.
- LSTMCell (
self.rnn):- The
LSTMCellis a simplified version of the LSTM layer that processes one time step at a time. It takes in both the embedding of the current decoder input and the context from the attention mechanism as inputs. - The
LSTMCellgenerates the new hidden and cell states at each time step.
- The
- Linear Layer (
self.out):- After generating the new hidden state, the decoder uses a linear layer (
nn.Linear) to map this hidden state to a probability distribution over the vocabulary (i.e., to predict the next token in the output sequence).
- After generating the new hidden state, the decoder uses a linear layer (
Decoder Forward Pass:
def forward(self, input, hidden, cell, encoder_outputs):
embedded = self.embed(input)
attended = self.attention(hidden, encoder_outputs)
rnn_input = torch.cat([embedded, attended], dim=2)
hidden, cell = self.rnn(rnn_input, (hidden, cell))
output = self.out(hidden)
return output, hidden, cell
- Input (
input): The current token in the target sequence (or the previously generated token in the case of auto-regressive decoding). - Embedding (
self.embed(input)): Converts the input token into its embedding representation. - Attention (
self.attention(hidden, encoder_outputs)): The decoder uses the hidden state from the previous time step and the encoder outputs to compute an attention vector that focuses on the most relevant parts of the encoder’s hidden states. - Concatenate (
torch.cat([embedded, attended], dim=2)): The attention vector is concatenated with the embedding of the current input token to form the input to the LSTM. - LSTMCell: The concatenated vector is passed through the LSTMCell to generate the new hidden and cell states.
- Linear Layer (
self.out(hidden)): The hidden state is mapped to a probability distribution over the vocabulary, predicting the next token in the sequence.
Attention Mechanism
The attention mechanism in this decoder helps solve the problem of using just the final hidden state of the encoder to summarize an entire sequence, which can cause information loss for long sequences. By using attention, the decoder can dynamically focus on different parts of the input sequence at each step, allowing it to attend to specific words or parts of the input that are most relevant for generating the current token in the output sequence.
3. Attention Mechanism in Transformer
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.output = nn.Linear(embed_dim, embed_dim)
def forward(self, query, key, value):
batch_size = query.size(0)
query = self.query(query).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
key = self.key(key).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
value = self.value(value).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.head_dim)
attention_weights = nn.functional.softmax(scores, dim=-1)
attended_values = torch.matmul(attention_weights, value)
attended_values = attended_values.permute(0, 2, 1, 3).contiguous().view(batch_size, -1, self.embed_dim)
output = self.output(attended_values)
return output
This code implements multi-head attention, a critical component in modern deep learning models, particularly in the Transformer architecture. Multi-head attention allows the model to attend to different parts of the input sequence simultaneously, which improves the learning of complex relationships in the data.
Understanding Multi-Head Attention from First Principles
Key Components of Multi-Head Attention:
- Multiple Attention Heads: Instead of using a single attention mechanism, we use multiple “heads” that each focus on different parts of the input sequence. Each head learns different attention patterns.
- Embedding Dimensionality Splitting: The model splits the input embedding into multiple smaller subspaces (equal to the number of heads) and applies attention to each subspace independently.
- Recombining the Heads: After applying attention independently in each head, the outputs are recombined and projected back to the original embedding size.
Breakdown of the Code
1. Initialization (__init__ Method)
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.output = nn.Linear(embed_dim, embed_dim)
- Embedding Dimensionality (
embed_dim): This is the size of the input embeddings. For example, in NLP tasks, this could be the size of the word embeddings. - Number of Heads (
num_heads): This refers to how many different attention “heads” we want. Each head will have its own independent attention mechanism. -
Head Dimensionality (
head_dim): The dimensionality of each head is calculated by dividingembed_dimbynum_heads. This ensures that the total size of the attention heads equals the original embedding size.For example, if
embed_dim = 512andnum_heads = 8, then each head will have a dimensionality ofhead_dim = 64. -
Query, Key, and Value Linear Layers: These are linear transformations used to compute the query, key, and value matrices, respectively. Each matrix transformation takes an input of size
embed_dimand projects it into a new space of sizeembed_dim. - Output Linear Layer (
self.output): After the attention heads have computed their independent attention scores, the outputs are concatenated and passed through another linear layer (self.output) to recombine them into the final representation.
2. Forward Pass (forward Method)
def forward(self, query, key, value):
batch_size = query.size(0)
query = self.query(query).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
key = self.key(key).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
value = self.value(value).view(batch_size, -1, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
-
Batch Size:
batch_size = query.size(0)extracts the batch size, which is the first dimension of the input tensors (query,key,value). - Project Queries, Keys, and Values:
- We first project the input tensors using the linear layers for
query,key, andvalue. Each of these projections has a shape of(batch_size, seq_len, embed_dim), whereseq_lenis the length of the input sequence. - Next, we reshape the projected queries, keys, and values to create multiple heads. This is done using the
viewmethod:query = query.view(batch_size, -1, self.num_heads, self.head_dim)After reshaping, the new shape is
(batch_size, seq_len, num_heads, head_dim), where:num_headsis the number of attention heads.head_dimis the dimensionality of each head.
- We first project the input tensors using the linear layers for
- Permute: We then use
permute(0, 2, 1, 3)to rearrange the dimensions of the tensor so that the shape becomes(batch_size, num_heads, seq_len, head_dim). This makes it easier to compute attention scores for each head independently.
3. Scaled Dot-Product Attention
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.head_dim)
attention_weights = nn.functional.softmax(scores, dim=-1)
attended_values = torch.matmul(attention_weights, value)
- Dot Product of Query and Key:
scores = torch.matmul(query, key.transpose(-2, -1))- The dot product between the query and the key is computed to get the attention scores. Since the shape of
queryis(batch_size, num_heads, seq_len_q, head_dim)and the shape ofkeyis(batch_size, num_heads, seq_len_k, head_dim), the result will have shape(batch_size, num_heads, seq_len_q, seq_len_k). - These scores represent how much attention each query should pay to each key.
- The dot product between the query and the key is computed to get the attention scores. Since the shape of
- Scaled Attention:
scores /= math.sqrt(self.head_dim)The scores are scaled by dividing them by the square root of
head_dim(i.e., the dimensionality of the queries and keys). This scaling helps prevent extremely large dot products, which can lead to vanishing gradients during training when passed through the softmax function. - Softmax Over Attention Scores:
attention_weights = nn.functional.softmax(scores, dim=-1)The softmax function is applied to the attention scores along the last dimension (
dim=-1), converting the scores into a probability distribution. These probabilities represent the attention weights. - Weighted Sum of Values:
attended_values = torch.matmul(attention_weights, value)After computing the attention weights, we use them to compute a weighted sum of the value vectors. This step gives us the attended values, which are the values weighted by the attention given to each key.
4. Recombining the Heads
attended_values = attended_values.permute(0, 2, 1, 3).contiguous().view(batch_size, -1, self.embed_dim)
output = self.output(attended_values)
- Rearranging Dimensions:
attended_values.permute(0, 2, 1, 3)After the attention heads have processed their respective parts of the sequence, we permute the tensor back to its original shape
(batch_size, seq_len, num_heads, head_dim). - Concatenate Attention Heads:
attended_values.view(batch_size, -1, self.embed_dim)We reshape the attended values by concatenating the attention heads back into a single tensor of shape
(batch_size, seq_len, embed_dim). This restores the original embedding dimensionality. - Final Output Projection:
output = self.output(attended_values)Finally, we apply a linear transformation to recombine the attention heads into the final output of the multi-head attention mechanism. The output shape will be
(batch_size, seq_len, embed_dim).
Summary of Multi-Head Attention
- Multiple Attention Heads: Multi-head attention splits the input embedding into multiple smaller subspaces, applies independent attention to each, and then concatenates them back together.
- Scoring Mechanism: The dot product between the query and key matrices produces attention scores, which are then scaled and passed through a softmax function to generate attention weights.
- Weighted Sum: The attention weights are applied to the value vectors to compute the attended values, which represent the parts of the input sequence that the model should focus on.
- Recombination: After applying attention independently to each head, the outputs are recombined and projected to the original embedding dimensionality.
This mechanism allows the model to focus on different aspects of the input sequence simultaneously, which helps it capture complex patterns and relationships in the data. Multi-head attention is a core component of models like Transformers and has been highly effective in tasks like machine translation, text generation, and more.
4. Attention mechanism in sequence to sequence models
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim, embed_dim, hidden_dim, num_layers):
super(Encoder, self).__init__()
self.embed = nn.Embedding(input_dim, embed_dim)
self.rnn = nn.LSTM(embed_dim, hidden_dim, num_layers, bidirectional=True)
def forward(self, input_seq, input_lengths):
embedded = self.embed(input_seq)
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
outputs, (hidden, cell) = self.rnn(packed)
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
return outputs, hidden, cell
class Decoder(nn.Module):
def __init__(self, output_dim, embed_dim, hidden_dim, num_layers, attention):
super(Decoder, self).__init__()
self.embed = nn.Embedding(output_dim, embed_dim)
self.rnn = nn.LSTMCell(embed_dim + hidden_dim, hidden_dim)
self.attention = attention
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, input, hidden, cell, encoder_outputs):
embedded = self.embed(input)
attended = self.attention(hidden, encoder_outputs)
rnn_input = torch.cat([embedded, attended], dim=1)
hidden, cell = self.rnn(rnn_input, (hidden, cell))
output = self.out(hidden)
return output, hidden, cell
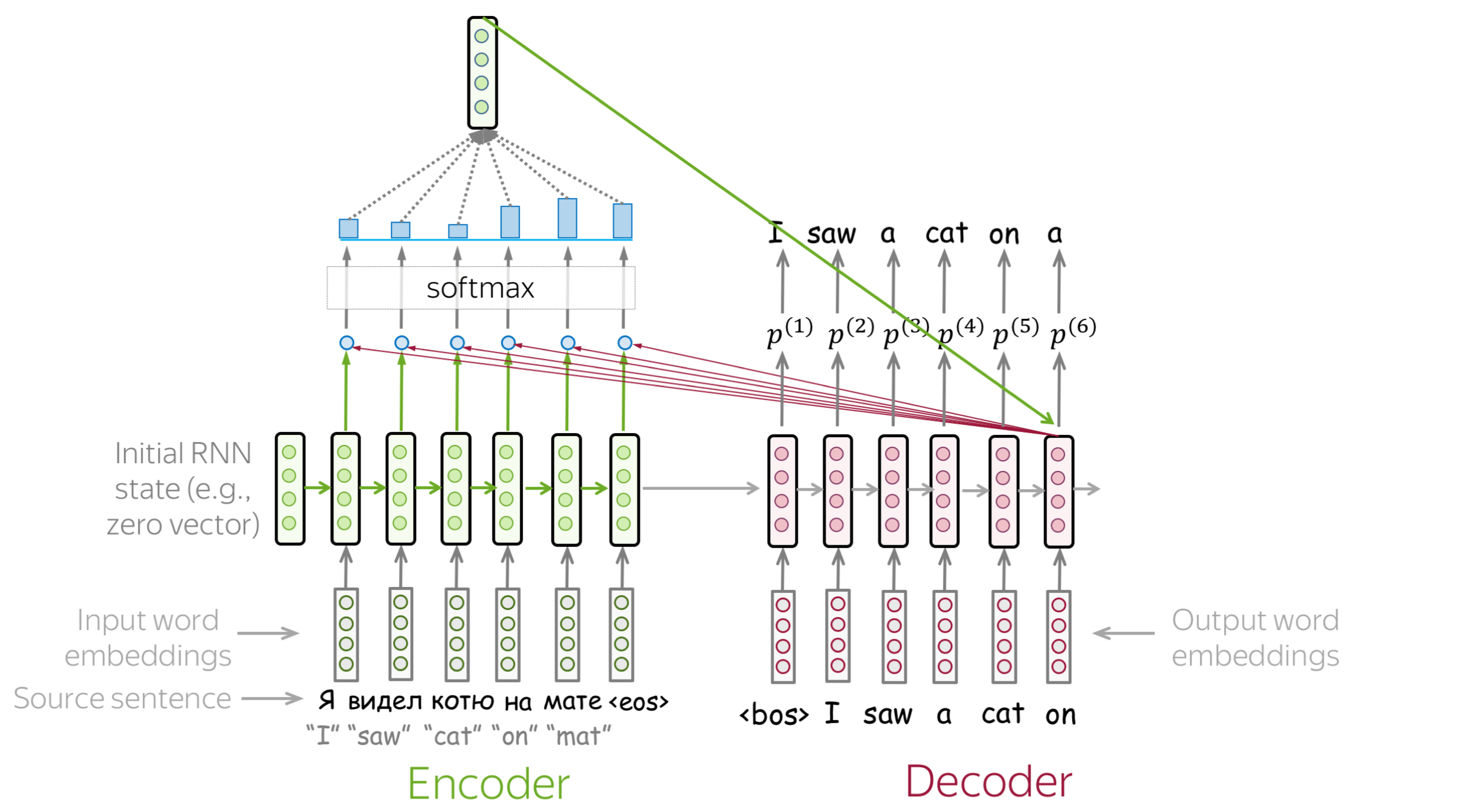
This code implements an Encoder-Decoder architecture with attention, where the encoder uses a bidirectional LSTM to encode the input sequence, and the decoder uses an LSTM cell to generate outputs from the encoded sequence while using attention to focus on specific parts of the input sequence. This setup is common in sequence-to-sequence (Seq2Seq) models used for tasks like machine translation, text summarization, and dialogue generation.
Breakdown of the Code from First Principles
Encoder
The encoder reads the input sequence, compresses it into a set of hidden states, and passes these hidden states to the decoder.
class Encoder(nn.Module):
def __init__(self, input_dim, embed_dim, hidden_dim, num_layers):
super(Encoder, self).__init__()
self.embed = nn.Embedding(input_dim, embed_dim)
self.rnn = nn.LSTM(embed_dim, hidden_dim, num_layers, bidirectional=True)
- Embedding Layer (
self.embed):- The input sequence is represented as a sequence of indices (tokens), which need to be converted to a continuous-valued vector representation. The
nn.Embeddinglayer does this by mapping each token index to anembed_dim-dimensional vector.
- The input sequence is represented as a sequence of indices (tokens), which need to be converted to a continuous-valued vector representation. The
- Bidirectional LSTM (
self.rnn):- The LSTM reads the input sequence in both directions (forward and backward) to capture both past and future context. This is achieved by setting
bidirectional=Truein thenn.LSTMlayer. A bidirectional LSTM processes the sequence twice: once from start to end and once from end to start. - The hidden dimension of each direction is
hidden_dim, but the actual hidden state size of the bidirectional LSTM will be2 * hidden_dim(since it concatenates the forward and backward states).
- The LSTM reads the input sequence in both directions (forward and backward) to capture both past and future context. This is achieved by setting
Forward Pass of the Encoder
def forward(self, input_seq, input_lengths):
embedded = self.embed(input_seq)
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
outputs, (hidden, cell) = self.rnn(packed)
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
return outputs, hidden, cell
- Input Sequence and Lengths:
input_seq: The input sequence (a batch of token indices).input_lengths: The actual lengths of the sequences in the batch, which are required to handle sequences of different lengths (padding).
- Embedding:
embedded = self.embed(input_seq)Each token in the input sequence is mapped to a continuous vector representation using the embedding layer. The output shape will be
(seq_len, batch_size, embed_dim). - Packing the Sequence:
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)Sequences in a batch can have different lengths, and this step packs the padded sequences into a compact format so that the LSTM doesn’t waste computations on the padding tokens.
- Bidirectional LSTM:
outputs, (hidden, cell) = self.rnn(packed)The packed sequence is passed through the bidirectional LSTM, which outputs:
outputs: The hidden states for each time step (for both directions).hidden: The final hidden states of the LSTM.cell: The final cell states of the LSTM.
- Padding the Sequence:
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)After processing the packed sequence, this function converts the output back to the padded format.
- Return Values:
The
Encoderreturns:outputs: The hidden states for every time step (concatenating both forward and backward hidden states for the bidirectional LSTM).hidden: The final hidden states of the LSTM.cell: The final cell states of the LSTM.
Decoder
The decoder generates the output sequence, one token at a time, using the hidden states from the encoder and applying attention to selectively focus on different parts of the input sequence.
class Decoder(nn.Module):
def __init__(self, output_dim, embed_dim, hidden_dim, num_layers, attention):
super(Decoder, self).__init__()
self.embed = nn.Embedding(output_dim, embed_dim)
self.rnn = nn.LSTMCell(embed_dim + hidden_dim, hidden_dim)
self.attention = attention
self.out = nn.Linear(hidden_dim, output_dim)
- Embedding Layer (
self.embed):- Like the encoder, the decoder also has an embedding layer that maps the input tokens (previously generated tokens) to dense vectors of size
embed_dim.
- Like the encoder, the decoder also has an embedding layer that maps the input tokens (previously generated tokens) to dense vectors of size
- LSTMCell (
self.rnn):- Unlike the encoder, which uses an
LSTM, the decoder uses anLSTMCell. The key difference is thatLSTMCellprocesses one time step at a time, making it more flexible for tasks where we generate outputs token by token. - The input to the
LSTMCellis the concatenation of the current token’s embedding and the attended context from the encoder.
- Unlike the encoder, which uses an
- Attention Mechanism (
self.attention):- The attention mechanism computes a weighted sum of the encoder’s hidden states to focus on the most relevant parts of the input sequence for generating the current output token. It takes the decoder’s current hidden state and the encoder’s outputs to compute attention weights.
- Output Layer (
self.out):- The hidden state from the
LSTMCellis passed through a linear layer that projects it to the vocabulary space (output_dim). This produces a probability distribution over the possible output tokens, allowing the model to predict the next token in the sequence.
- The hidden state from the
Forward Pass of the Decoder
def forward(self, input, hidden, cell, encoder_outputs):
embedded = self.embed(input)
attended = self.attention(hidden, encoder_outputs)
rnn_input = torch.cat([embedded, attended], dim=1)
hidden, cell = self.rnn(rnn_input, (hidden, cell))
output = self.out(hidden)
return output, hidden, cell
- Input Token Embedding:
embedded = self.embed(input)The current input token is mapped to its embedding using the embedding layer. The shape will be
(batch_size, embed_dim). - Attention Mechanism:
attended = self.attention(hidden, encoder_outputs)The attention mechanism uses the decoder’s current hidden state (
hidden) and the encoder’s outputs (encoder_outputs) to compute attention scores. The result,attended, is a weighted sum of the encoder’s hidden states, focusing on the parts of the input sequence that are most relevant for generating the current token. - Concatenating Embedding and Attended Context:
rnn_input = torch.cat([embedded, attended], dim=1)The decoder concatenates the current input token’s embedding and the attended context from the encoder. This combined input is fed into the
LSTMCell. - LSTMCell:
hidden, cell = self.rnn(rnn_input, (hidden, cell))The
LSTMCelltakes the combined input and updates its hidden and cell states. This process is repeated for each time step of the output sequence, allowing the decoder to generate the sequence token by token. - Output Layer:
output = self.out(hidden)The updated hidden state is passed through the output linear layer, which projects it to the output vocabulary space (
output_dim). This gives a probability distribution over the next possible tokens.
Attention Mechanism in Context
In sequence-to-sequence tasks, especially when dealing with long input sequences, the encoder’s final hidden state may not be enough to capture all relevant information. The attention mechanism addresses this by allowing the decoder to selectively focus on different parts of the input sequence at each decoding step.
In this code, the attention mechanism computes a context vector as a weighted sum of the encoder’s outputs, with the weights determined by the similarity between the decoder’s hidden state and each encoder output. This allows the decoder to “attend” to different parts of the input sequence based on the current state of decoding.
Summary
- Encoder: A bidirectional LSTM processes the input sequence from both directions and produces hidden states that summarize the input sequence.
- Decoder: An LSTM cell generates the output sequence token by token. At each step, the decoder uses attention to focus on the relevant parts of the input sequence, guided by the encoder’s hidden states.
- Attention: The attention mechanism allows the decoder to dynamically focus on specific parts of the input sequence, improving its ability to handle long or complex sequences.
This encoder-decoder architecture is commonly used in applications like machine translation, text summarization, and speech recognition. The attention mechanism is especially useful for aligning input and output sequences that may have different lengths.
5. Attention mechanism in transformer language models
import torch
import torch.nn as nn
class TransformerEncoderBlock(nn.Module):
def __init__(self, embed_dim, num_heads, ffn_dim, dropout):
super(TransformerEncoderBlock, self).__init__()
self.attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
self.ffn = nn.Sequential(
nn.Linear(embed_dim, ffn_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(ffn_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x, mask=None):
attended, _ = self.attention(x, x, x, key_padding_mask=mask)
x = x + attended
x = x + self.ffn(x)
return x
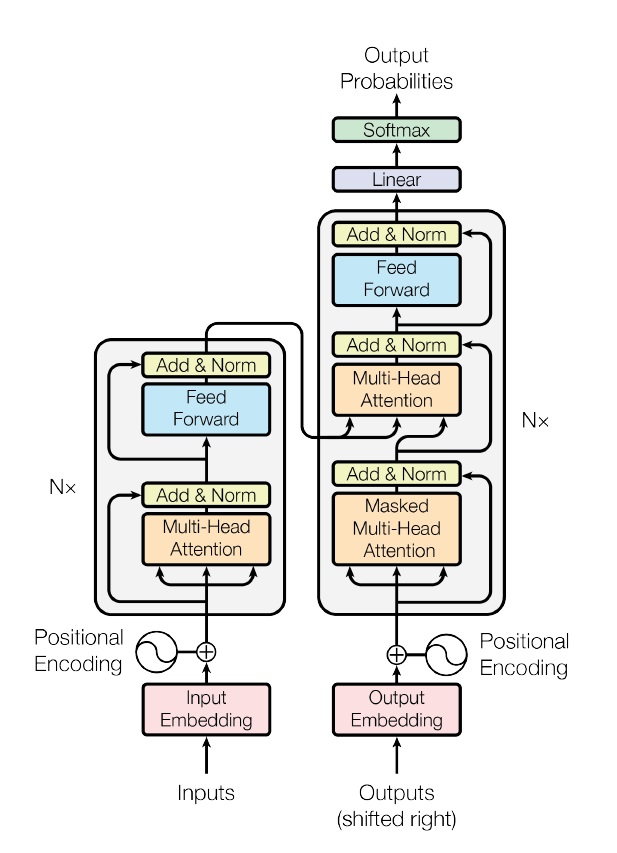
This code implements a Transformer Encoder Block, a key component in Transformer architectures used for tasks like machine translation, language modeling, and other sequence-based tasks. The Transformer architecture was introduced in the paper “Attention Is All You Need” (Vaswani et al., 2017) and relies on self-attention mechanisms instead of recurrence (as in RNNs or LSTMs) to process sequences in parallel.
Let’s break down the code from first principles, focusing on the purpose of each component and how it works within the block.
Transformer Encoder Block Breakdown
A Transformer encoder block is composed of two main components:
- Multi-head Self-Attention Mechanism: This allows the model to focus on different parts of the input sequence simultaneously.
- Feedforward Neural Network (FFN): This applies further transformation to the attended inputs.
In addition, residual connections (skip connections) and layer normalization are typically applied after the attention and feedforward layers to help with training stability.
1. Initialization (__init__ method)
class TransformerEncoderBlock(nn.Module):
def __init__(self, embed_dim, num_heads, ffn_dim, dropout):
super(TransformerEncoderBlock, self).__init__()
self.attention = nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
self.ffn = nn.Sequential(
nn.Linear(embed_dim, ffn_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(ffn_dim, embed_dim),
nn.Dropout(dropout)
)
Key Components:
- Multi-head Attention (
self.attention):nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout):- This is the multi-head self-attention mechanism that allows the model to focus on different parts of the input sequence. The
embed_dimdefines the size of the input embeddings, whilenum_headsdetermines how many independent attention “heads” the model uses. Each head performs attention in a different subspace of the input. - Dropout is applied to prevent overfitting and improve generalization.
- Self-attention means that each position in the sequence attends to all other positions in the sequence, allowing the model to capture long-range dependencies.
- This is the multi-head self-attention mechanism that allows the model to focus on different parts of the input sequence. The
- Feedforward Neural Network (FFN) (
self.ffn):nn.Linear(embed_dim, ffn_dim): This is the first linear layer that expands the embedding size to a higher-dimensional space (typicallyffn_dim > embed_dim). This allows the model to learn more complex transformations.nn.ReLU(): This activation function introduces non-linearity to the feedforward network.- Dropout: Applied to prevent overfitting.
nn.Linear(ffn_dim, embed_dim): This layer projects the higher-dimensional space back to the original embedding dimension. This ensures that the input and output dimensions remain consistent throughout the transformer block.- The FFN is applied independently to each position in the sequence.
2. Forward Pass (forward method)
def forward(self, x, mask=None):
attended, _ = self.attention(x, x, x, key_padding_mask=mask)
x = x + attended
x = x + self.ffn(x)
return x
Multi-Head Self-Attention:
attended, _ = self.attention(x, x, x, key_padding_mask=mask)
-
Self-attention: The inputs
xare passed through the multi-head attention layer. In self-attention, the query (Q), key (K), and value (V) matrices are all the same input (x). This allows each token in the sequence to attend to every other token.-
Key Padding Mask (
mask): This mask is used to ignore padded tokens during attention, ensuring that the model does not focus on padding (commonly used for sequences of varying lengths). -
The result,
attended, is the output of the attention mechanism, which contains information about which tokens attended to which other tokens in the sequence.
-
Residual Connection and Attention Addition:
x = x + attended
- Residual Connection: The attended output is added back to the original input (
x), forming a skip connection. Residual connections are crucial for stabilizing training and helping the gradients propagate more easily through deep networks. This allows the model to preserve the original information while learning attention-based modifications.
Feedforward Network and Residual Connection:
x = x + self.ffn(x)
-
After the attention mechanism, the input is passed through the feedforward neural network (
self.ffn(x)), which applies a series of linear transformations, activations, and dropout to enhance the feature representations. -
Another Residual Connection: The output of the feedforward network is added back to the original input (after attention), forming another skip connection. This ensures that both the attention-modified input and the feedforward-modified input are combined.
Final Output:
The final output x is returned. This output has the same shape as the input but has been transformed through attention and feedforward layers, capturing relationships between tokens and further refining the feature representations.
What Does This Block Do?
-
Self-Attention: The
nn.MultiheadAttentionlayer allows each token to attend to every other token in the sequence. The attention mechanism computes attention scores and creates a weighted sum of the value vectors based on the importance (attention) of each token. -
Residual Connections: By adding the input (
x) back after the attention and feedforward transformations, the model can propagate both the original information and the modifications learned from attention and the feedforward network. This helps with gradient flow and ensures that the input representation is retained even after many layers. -
Feedforward Network: The FFN applies further transformations to each position in the sequence independently. The two linear layers with ReLU activation allow the model to learn more complex transformations that capture dependencies in the data.
-
Masking: The
key_padding_mask=maskensures that padded positions (which are added to make sequences of equal length) are ignored during attention calculations, preventing the model from attending to irrelevant tokens.
Transformer Encoder Block Summary
This block is a fundamental building block of the Transformer architecture. In a full Transformer encoder, multiple such blocks are stacked on top of each other to form a deep model. Each block refines the representation of the input sequence through self-attention and a feedforward neural network, while residual connections help stabilize training.
The key advantages of using a Transformer encoder block over traditional RNN-based models are:
- Parallelization: Transformers allow parallel processing of sequence data, unlike RNNs, which process sequences sequentially.
- Long-Range Dependencies: The self-attention mechanism can capture dependencies between distant tokens in the input sequence, addressing the limitations of RNNs and LSTMs in handling long-range dependencies.
This block can be used for various sequence-processing tasks, such as language modeling, translation, or even image processing (e.g., in Vision Transformers).